Abstract
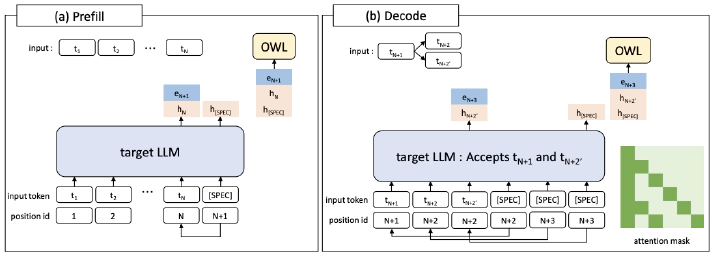
Speculative decoding promises faster inference for large language models (LLMs), yet existing methods fail to generalize to real-world settings. Benchmarks typically assume short contexts (e.g., 2K tokens), whereas practical workloads involve long contexts. We find current approaches degrade severely with long contexts; for instance, EAGLE3 even slows down the generation speed by 0.81x. We address these limitations by releasing a new long-context benchmark (LongSpecBench) and introducing a novel model (OWL). OWL achieves about 5x higher acceptance length than EAGLE3 on long-context inputs through three innovations: (1) an LSTM-based drafter conditioned only on the last-token state, making it generalize to various lengths, (2) a special token [SPEC] in the verifier that produces richer representation for drafter, and (3) a hybrid algorithm combining both tree and non-tree decoding methods. We release all code and datasets to advance future research.