FlexLLM: Token-Level Co-Serving of LLM Inference and Finetuning with SLO Guarantees
Abstract
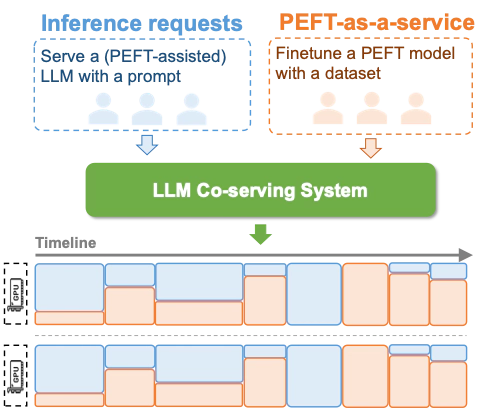
Finetuning large language models (LLMs) is essential for task adaptation, yet today’s serving stacks isolate inference and finetuning on separate GPU clusters–wasting resources and under-utilizing hardware. We introduce FlexLLM, the first system to co-serve LLM inference and PEFT-based finetuning on shared GPUs by fusing computation at the token level. FlexLLM’s static compilation optimizations–dependent parallelization and graph pruning significantly shrink activation memory, leading to end-to-end GPU memory savings by up to 80%. At runtime, a novel token-level finetuning mechanism paired with a hybrid token scheduler dynamically interleaves inference and training tokens within each co-serving iteration, meeting strict latency SLOs while maximizing utilization. In end-to-end benchmarks on LLaMA-3.1-8B, Qwen-2.5-14B, and Qwen-2.5-32B, FlexLLM maintains inference SLO compliance at up to 20 req/s, and improves finetuning throughput by 1.9-4.8x under heavy inference workloads and 2.5-6.8x under light loads, preserving over 76% of peak finetuning progress even at peak demand. FlexLLM is publicly available at https://flexllm.github.io.